netstat timer keepalive RTO explain
netstat 等网络工具
netstat 和重传– timer
经常碰到一些断网环境下需要做快速切换,那么断网后需要多久tcp才能感知到这个断网,并断开连接触发上层的重连(一般会连向新的server)
netstat -st命令中,tcp: 部分取自/proc/net/snmp,而TCPExt部分取自/proc/net/netstat,该文件对TCP记录了更多的统计。sysstat包也会采集/proc/net/snmp
keepalive
from: https://superuser.com/questions/240456/how-to-interpret-the-output-of-netstat-o-netstat-timers
The timer column has two fields (from your o/p above):
1 | keepalive (6176.47/0/0) |
The 1st field can have values:
keepalive - when the keepalive timer is ON for the socket
on - when the retransmission timer is ON for the socket
off - none of the above is ON
on - #表示是重发(retransmission)的时间计时
off - #表示没有时间计时
timewait - #表示等待(timewait)时间计时
keepalive 是指在连接闲置状态发送心跳包来检测连接是否还有效(比如对方掉电后肯定就无效了,tcp得靠这个keepalive来感知)。如果有流量在传输过程中对方掉电后会不停地 retransmission ,这个时候看到的就是 on,然后重传间隔和次数跟keepalive参数无关,只和 net.ipv4.tcp_retries1、net.ipv4.tcp_retries2相关了。
keepalive 状态下的连接:

1 | #netstat -anto |grep -E ":3048|Q" | awk '{ if($3>0) print $0 }' |
The 2nd field has THREE subfields:
(6176.47/0/0) -> (a/b/c)
a=timer value (a=keepalive timer, when 1st field=“keepalive”; a=retransmission timer, when 1st field=“on”)
b=number of retransmissions that have occurred
c=number of keepalive probes that have been sent
/proc/sys/net/ipv4/tcp_keepalive_time
当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时。/proc/sys/net/ipv4/tcp_keepalive_intvl
当探测没有确认时,重新发送探测的频度。缺省是75秒。/proc/sys/net/ipv4/tcp_keepalive_probes
在认定连接失效之前,发送多少个TCP的keepalive探测包。缺省值是9。这个值乘以tcp_keepalive_intvl之后决定了,一个连接发送了keepalive之后可以有多少时间没有回应
For example, I had two sockets opened between a client & a server (not loopback). The keepalive setting are:
KEEPALIVE_IDLETIME 30
KEEPALIVE_NUMPROBES 4
KEEPALIVE_INTVL 10
And I did a shutdown of the client machine, so at …SHED on (2.47/254/2)
1 | tcp 0 210 192.0.0.1:36483 192.0.68.1:43881 ESTABLISHED on (1.39/254/2) |
As you can see, in this case things are a little different. When the client went down, my server started sending keepalive messages, but while it was still sending those keepalives, my server tried to send a message to the client. Since the client had gone down, the server couldn’t get any ACK from the client, so the TCP retransmission started and the server tried to send the data again, each time incrementing the retransmit count (2nd field) when the retransmission timer (1st field) expired.
Hope this explains the netstat –timer option well.
RTO 重传
1 | #define TCP_RTO_MAX ((unsigned)(120*HZ)) //HZ 通常为1秒 |
Linux 2.6+ uses HZ of 1000ms, so TCP_RTO_MIN is ~200 ms and TCP_RTO_MAX is ~120 seconds. Given a default value of tcp_retries set to 15, it means that it takes 924.6 seconds before a broken network link is notified to the upper layer (ie. application), since the connection is detected as broken when the last (15th) retry expires.
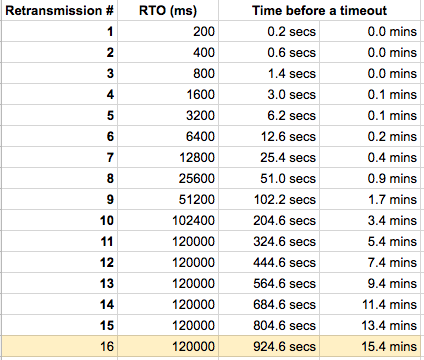
The tcp_retries2 sysctl can be tuned via /proc/sys/net/ipv4/tcp_retries2 or the sysctl net.ipv4.tcp_retries2.
查看重传状态
重传状态的连接:

前两个 syn_sent 状态明显是 9031端口不work了,握手不上。
最后 established 状态的连接, 是22端口给53795发了136字节的数据但是没有收到ack,所以在倒计时准备重传中。
net.ipv4.tcp_retries1 = 3
放弃回应一个TCP 连接请求前﹐需要进行多少次重试。RFC 规定最低的数值是3﹐这也是默认值﹐根据RTO的值大约在3秒 - 8分钟之间。(注意:这个值同时还决定进入的syn连接)
(第二种解释:它表示的是TCP传输失败时不检测路由表的最大的重试次数,当超过了这个值,我们就需要检测路由表了)
从kernel代码可以看到,一旦重传超过阈值tcp_retries1,主要的动作就是更新路由缓存。
用以避免由于路由选路变化带来的问题。这个时候tcp连接没有关闭
net.ipv4.tcp_retries2 = 15
**在丢弃激活(已建立通讯状况)**的TCP连接之前﹐需要进行多少次重试。默认值为15,根据RTO的值来决定,相当于13-30分钟(RFC1122规定,必须大于100秒).(这个值根据目前的网络设置,可以适当地改小,我的网络内修改为了5)
(第二种解释:表示重试最大次数,只不过这个值一般要比上面的值大。和上面那个不同的是,当重试次数超过这个值,我们就必须关闭连接了)
from:Documentation/networking/ip-sysctl.txt
1 | tcp_retries1 - INTEGER |

retries限制的重传次数吗
咋一看文档,很容易想到retries的数字就是限定的重传的次数,甚至源码中对于retries常量注释中都写着”This is how many retries it does…”
1 | #define TCP_RETR1 3 /* |
那就就来看看retransmits_timed_out的具体实现,看看到底是不是限制的重传次数
1 | /* This function calculates a "timeout" which is equivalent to the timeout of a |
从以上的代码分析可以看到,真正起到限制重传次数的并不是真正的重传次数。
而是以tcp_retries1或tcp_retries2为boundary,以rto_base(如TCP_RTO_MIN 200ms)为初始RTO,计算得到一个timeout值出来。如果重传间隔超过这个timeout,则认为超过了阈值。
上面这段话太绕了,下面举两个个例子来说明
2
3
4
5
6
7
8
1. 如果RTT比较小,那么RTO初始值就约等于下限200ms
由于timeout总时长是924600ms,表现出来的现象刚好就是重传了15次,超过了timeout值,从而放弃TCP流
2. 如果RTT较大,比如RTO初始值计算得到的是1000ms
那么根本不需要重传15次,重传总间隔就会超过924600ms。
比如我测试的一个RTT=400ms的情况,当tcp_retries2=10时,仅重传了3次就放弃了TCP流
一些重传的其它问题
1 | >> effective timeout指的是什么? |
RTO重传案例
我们来看如下这个51432端口向9627端口上传过程,十分缓慢,重传包间隔基本是122秒,速度肯定没法快
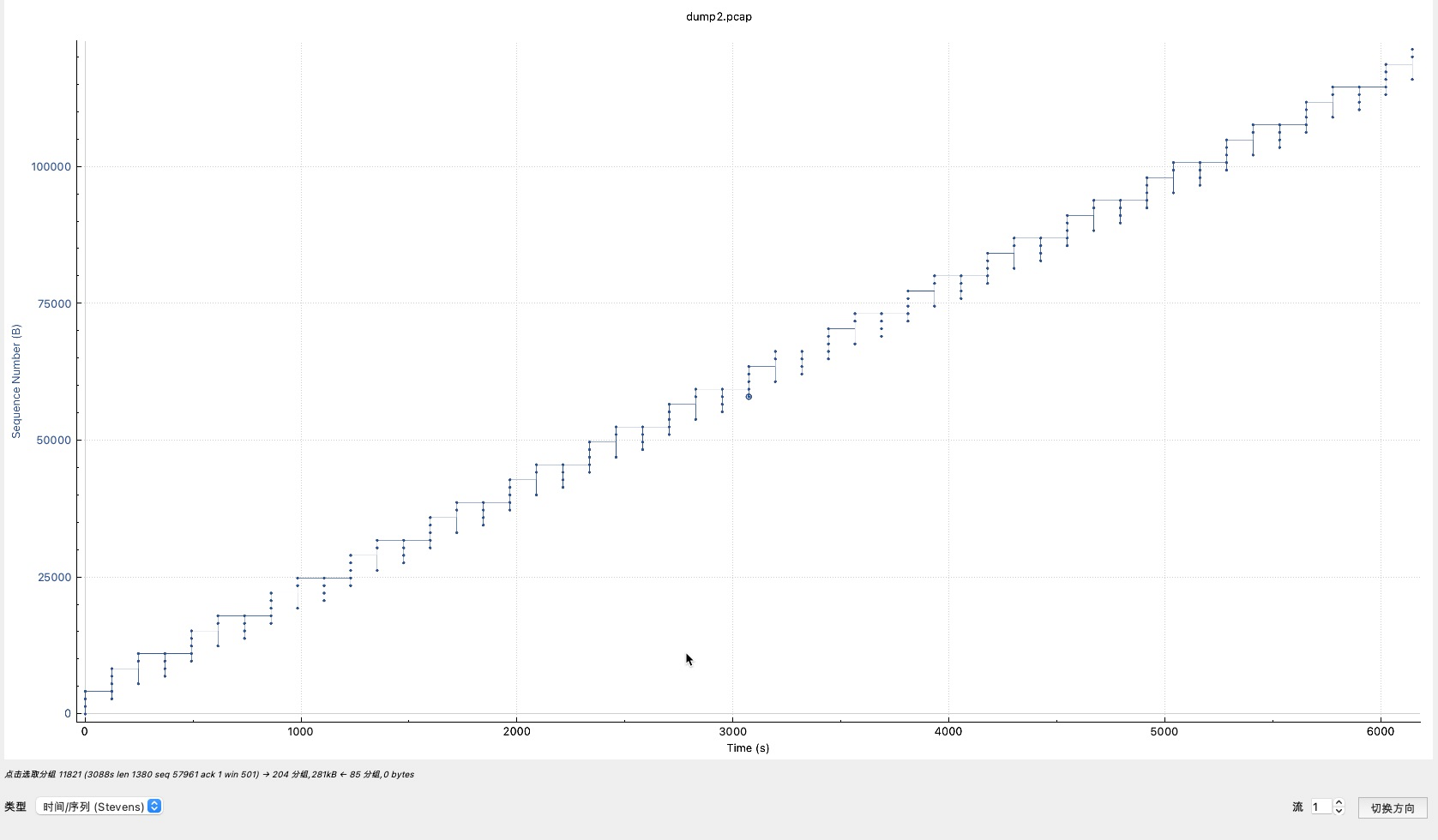
上图中垂直方向基本都是发出3-5个包,然后休息120秒,继续发3-5个 包,速度肯定慢,下图可以看到具体的包:
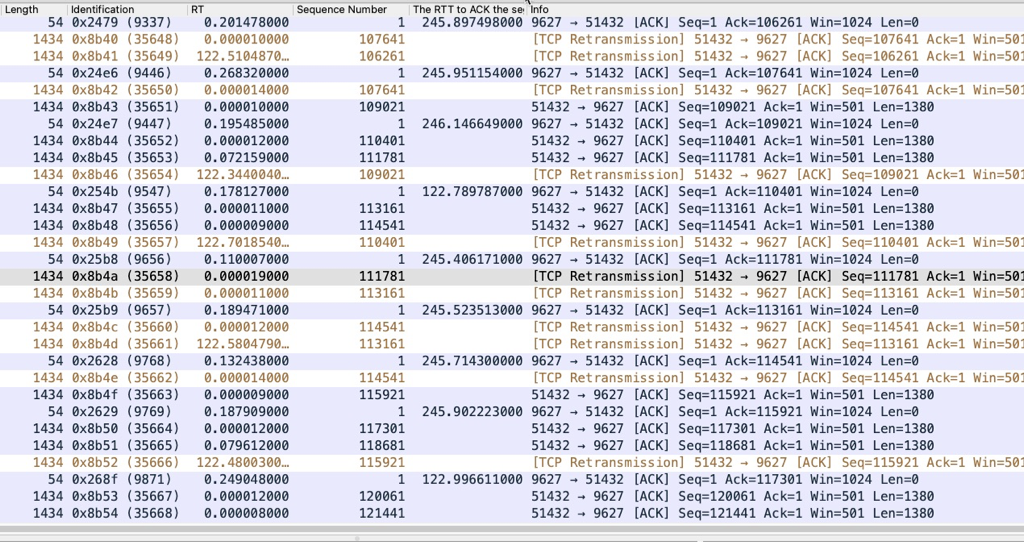
来看下到9627的RTT,基本稳定在245秒或者122秒,这RTT也实在太大了。可以看到:
网络质量很不好,丢包有点多;
rtt高得离谱,导致rto计算出来120秒了,所以一旦丢包就卡120秒以上。
下图是RTT图
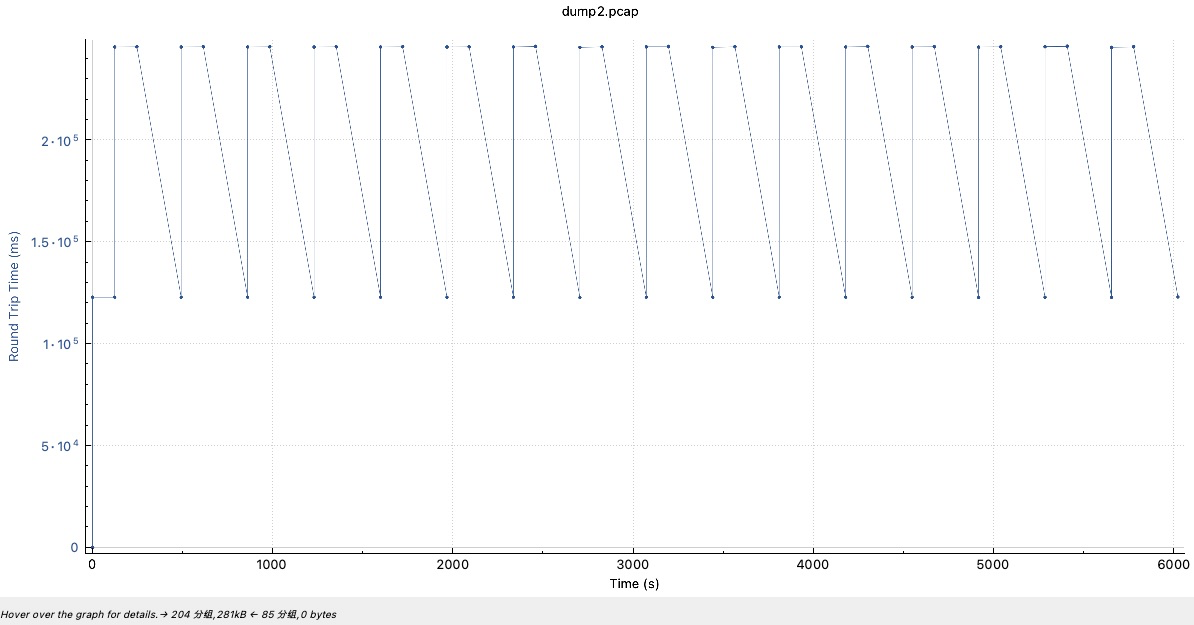
两个原因一叠加,就出现了奇慢无比.
正常情况下RTO是从200ms开始翻倍,实际上OS层面限制了最小RTO 200ms、最大RTO 120秒,由于RTT都超过120秒了,计算所得的RTO必定也大于120秒,所以最终就是我们看到的一上来第一个RTO不是常见的200ms,直接干到了120秒。
netstat -s
netstat -s统计,有两个和timestamp stamp reject相关的。
1 | netstat -st | grep stamp | grep reject |
丢包统计:
netstat -s |egrep -i “drop|route|overflow|filter|retran|fails|listen”
nstat -z -t 1 | egrep -i “drop|route|overflow|filter|retran|fails|listen”
netstat -st命令中,Tcp: 部分取自/proc/net/snmp,而TCPExt部分取自/proc/net/netstat,该文件对TCP记录了更多的统计。sysstat包也会采集/proc/net/snmp
nc 测试
1 | nc -v -u -z -w 3 10.101.0.1 53 //测试server 的53端口上的udp服务能否通 |
nc 6.5 快速fin
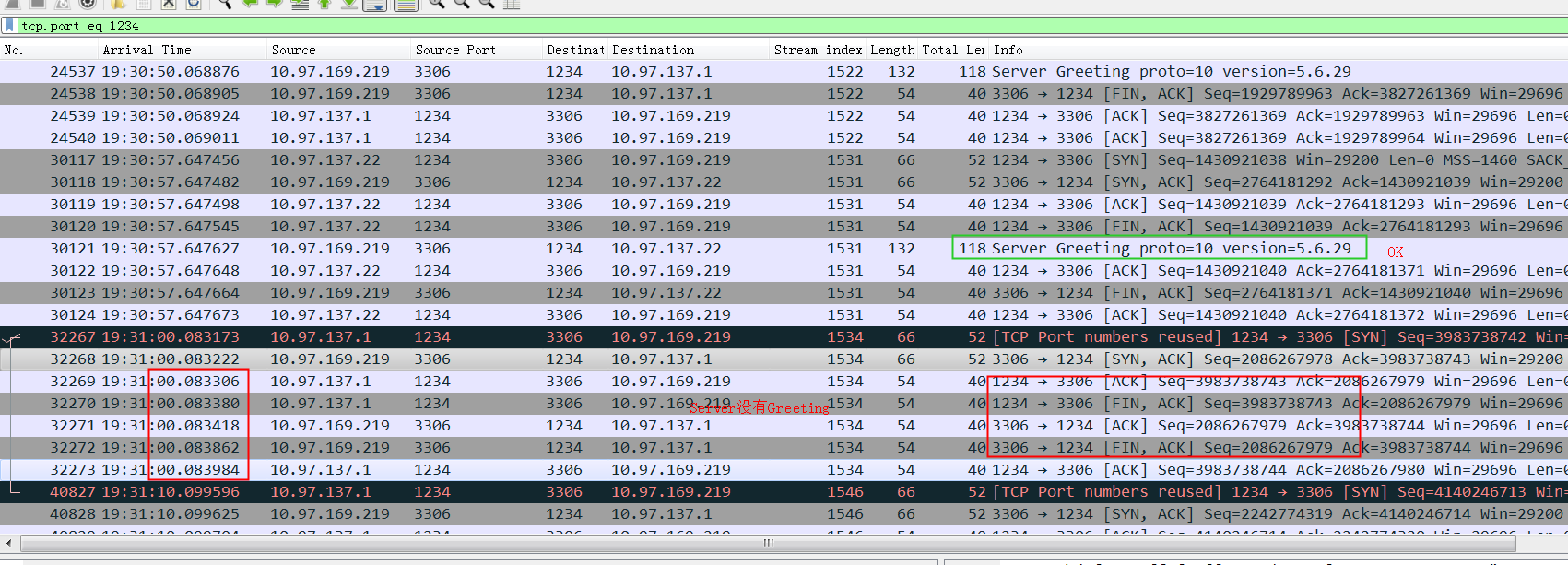
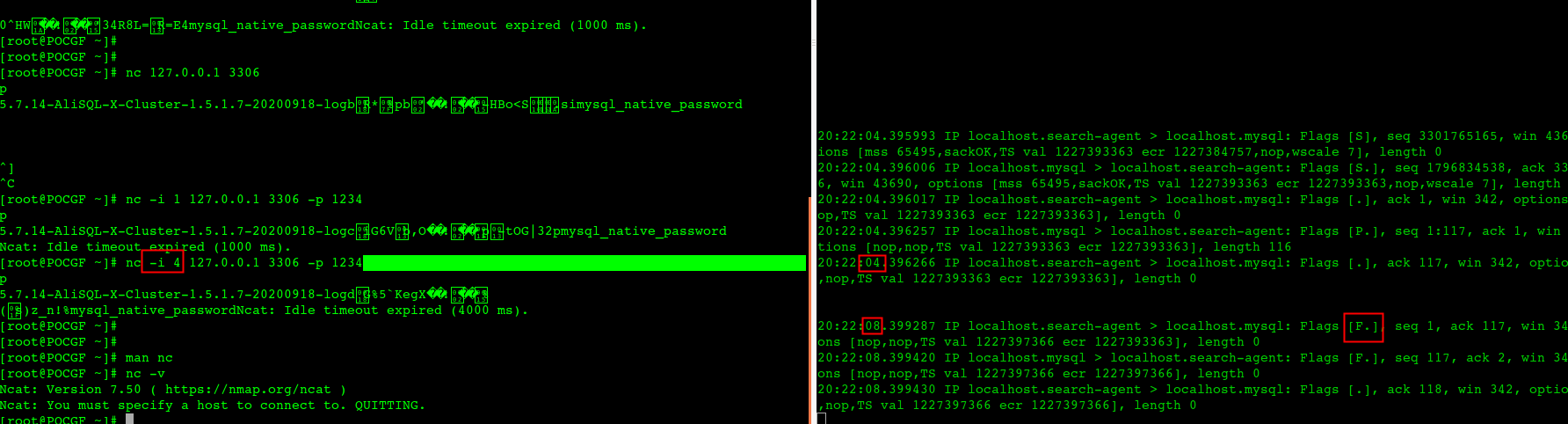
nc -i 3 10.97.170.11 3306 -w 4 -p 1234
-i 3 表示握手成功后 等三秒钟nc退出(发fin)
nc 6.5 握手后立即发fin断开连接,导致可能收不到Greeting,换成7.5或者mysql client就OK了
也就是用nc 6.5来验证mysql 服务是否正常可能会碰到nc自己断的太快,实际mysql还是正常的,从而像是mysql没有回复Greeting,从而产生误判。
nc 7.5的抓包,明显可以看到nc在发fin前会先等3秒钟:
ping
sudo ping -f ip 大批量的icmp包
ping -D 带时间戳 或者:ping -i 5 google.com | xargs -L 1 -I ‘{}’ date ‘+%Y-%m-%d %H:%M:%S: {}’ 或者 ping www.google.fr | while read pong; do echo “$(date): $pong”; done
ping -O 不通的时候输出:no answer yet for icmp_seq=xxx
或者-D + awk
ping -D 114.114.114.114 | awk ‘{ if(gsub(/[|]/, “”, $1)) $1=strftime(“[%F %T]”, $1); print}’
Linux 下直接增加如下函数:
1 | ping.ts(){ |
mtr
若需要将mtr的结果提供给第三方,建议可以使用-rc参数,r代表不使用交互界面,而是在最后给出一个探测结果报告;c参数指定需要作几次探测(一般建议是至少200个包,可以配合-i参数减少包间隔来加快得到结果的时间)。
traceroute
和mtr不同的是,traceroute默认使用UDP作为四层协议,下层还是依靠IP头的TTL来控制中间的节点返回ICMP差错报文,来获得中间节点的IP和延时。唯一的区别是,在达到目标节点时,若是ICMP协议,目标大概率是会回复ICMP reply;如果是UDP协议,按照RFC协议规定,系统是要回复ICMP 端口不可达的差错报文,虽然三大平台Windows/macOS/Linux都实现了这个行为,但出于某些原因,这个包可能还是会在链路上被丢弃,导致路由跟踪的结果无法显示出最后一跳。所以建议在一般的情况下,traceroute命令可以加上-I参数,让程序使用ICMP协议来发送探测数据包。
dstat

dstat -cdgilmnrsy –aio –fs –lock –raw